Your LLM thinks. MemBrain remembers, decides, and protects.
LLMs are the creative cortex of AI. MemBrain is the rest of the brain — memory across teams and agents, threat detection on every request, judgment about what's safe to do, signal routing to the right model. Self-hosted, between every employee and every model.
Threat detection scrubs PII before it hits cache keys or audit logs. Cached responses feed memory. Memory feeds the next prompt. One pipeline, one audit trail.
🧠
Memory
Every LLM response gets chunked, scored, and stored in a pgvector knowledge base with semantic dedup. The next prompt about the same topic gets the prior answer injected as context — before it reaches the model.
🛡
Threat detection
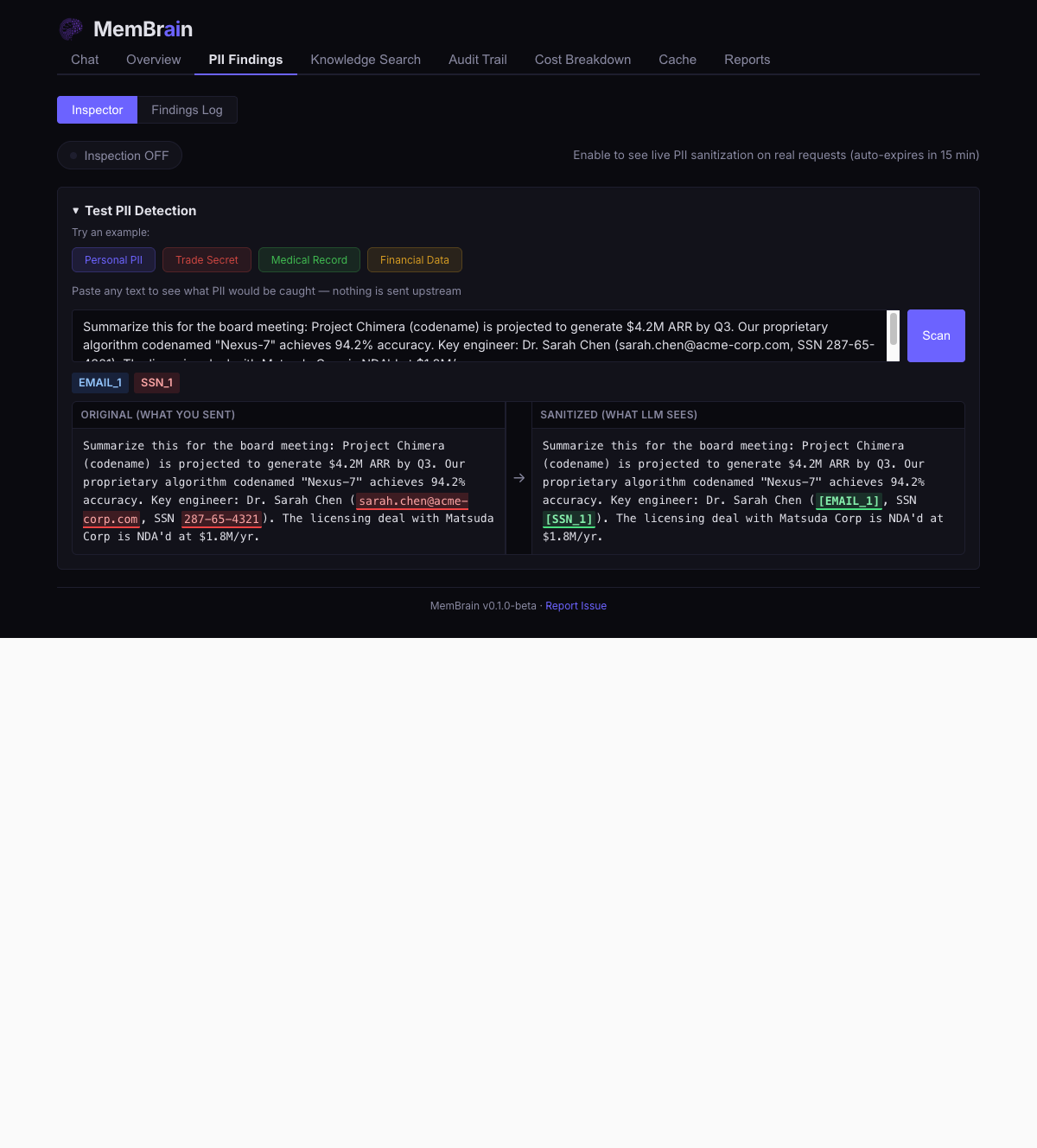
25+ PII patterns plus optional ML NER fire on every proxied request, before caching, before logging, before the LLM sees anything. Cache keys and audit logs are scrubbed of detected PII before write.
⚖
Judgment
Tool policy enforcement (fnmatch globs), rate limits, budget caps, and human-in-the-loop approval for destructive actions. Deliberate, rule-based decisions about what the model is allowed to do.
🔀
Attention
Routing decisions weigh privacy (sensitive requests go local), cost (cheapest provider that fits the tier), and latency (sorted fallback chains). The right signal to the right model.
🌙
Consolidation
A scheduled background job replays your knowledge store, marks stale entries, merges near-duplicates, and prunes low-quality memories. Sleep cycles for your AI.
👥
Coordination
Multi-agent teams (and human teammates) work in the same project without stepping on each other. Cross-actor memory surfaces, atomic work queues, declared-scope tasks with auto-generated handoffs. More →
NEW · Multi-Actor Coordination
Built for human teams and agent fleets
When multiple actors work in the same project — across timezones, across an agent fleet, or both — MemBrain coordinates them. Every chat already flows through; the substrate already knows who's doing what.
💡
See what teammates already asked
When you start a chat, MemBrain shows related Q&A from your team in a side card. You decide what to use — nothing is added to the prompt without a click. Detected PII gets redacted to canonical labels before it crosses actors.
🪝
A shared inbox for humans and agents
Agents escalate decisions to a person, hand off long-running work, or flag duplicates — and pick up tasks meant for them without stepping on each other. One Python SDK call to enqueue, claim, or complete.
📌
Pinned threads
Mark a conversation as available for continuation by a teammate or your future self. Auto-surfaced matches redact detected PII; pinning is the path that shares the conversation as-is — the originator opts in by pinning.
🗺️
Task coordination + handoff
Declare what files you're touching at checkout. Get a warning if your diff overlaps another in-flight task. On checkin, MemBrain pulls the transcript, extracts a structured summary, and leaves it for the next agent to read before starting related work.
Audit, REST, SDK, and dashboard for all four surfaces —
explore the docs →
See It In Action
A dashboard for everything your LLM doesn't know
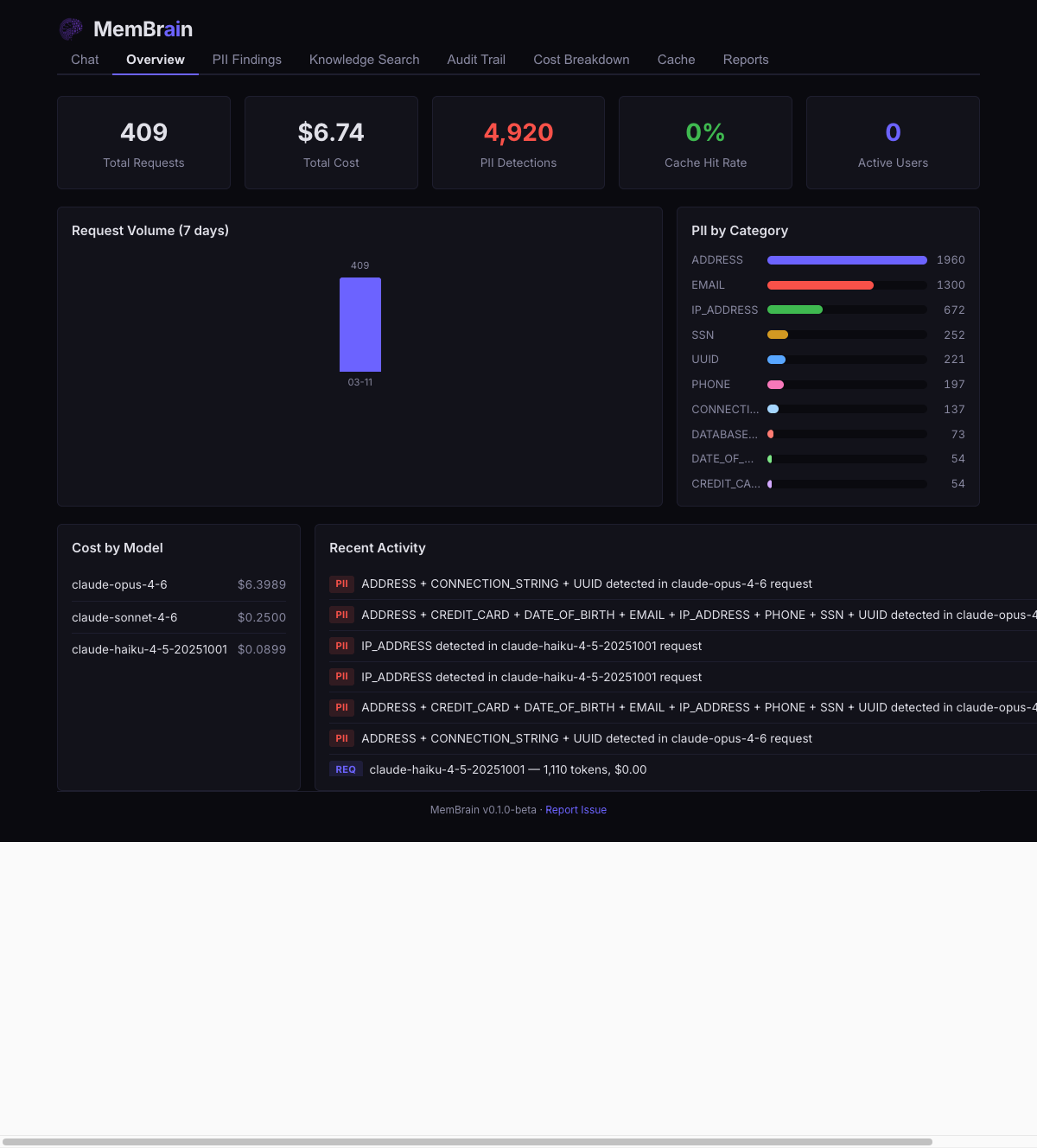
Real-time visibility into every AI interaction across your organization.
Overview DashboardRequest metrics, cost tracking, and system health at a glance
PII InspectorSee exactly what was detected and redacted in real time
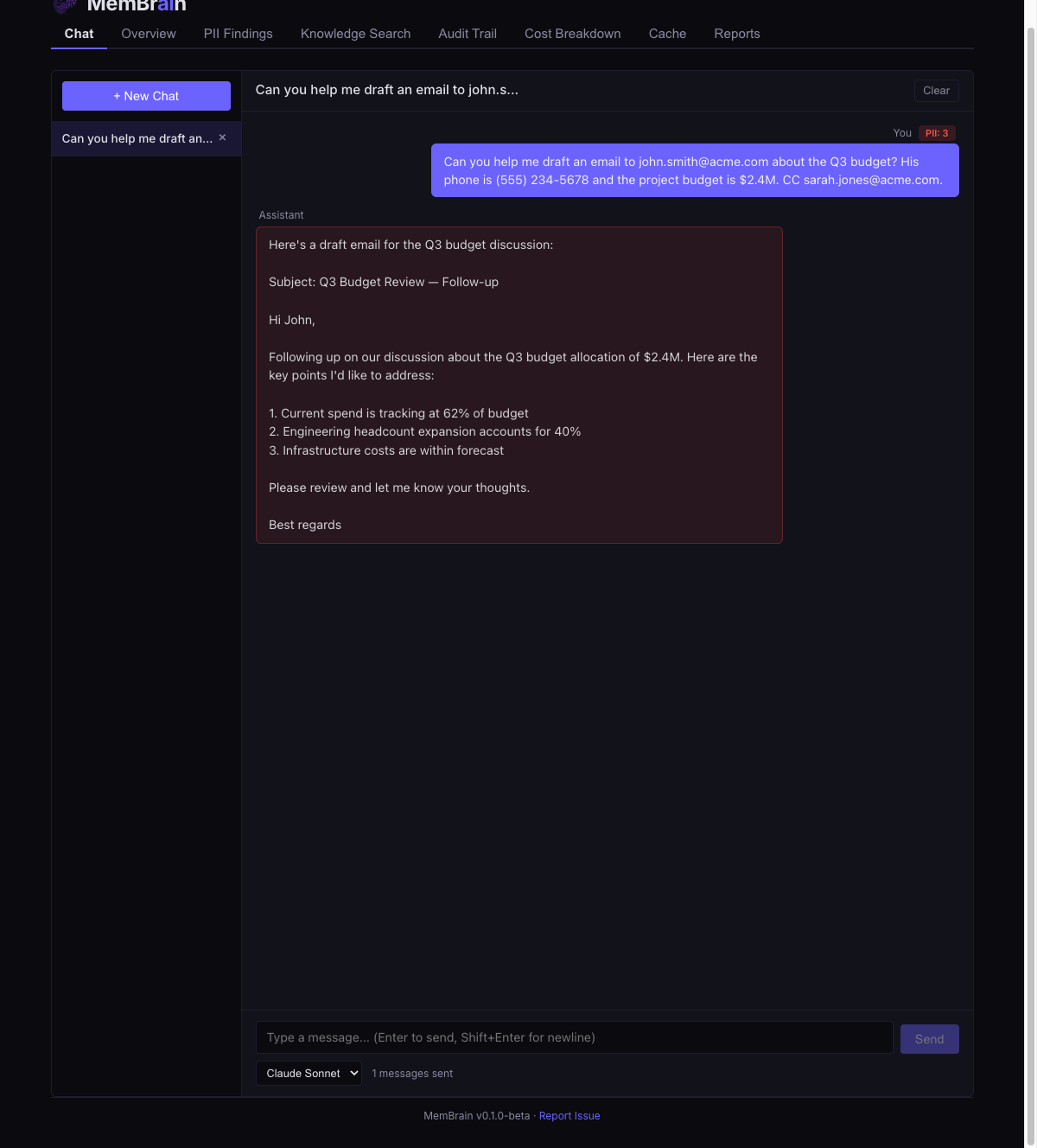
Built-in ChatTest models through the gateway with live PII badges
Multi-Layer Architecture
Cognition at every level
One brain per scope — personal, team, organization. Memory, policy, and threat detection cascade up; the org sets the floor, teams set their own, individuals add their own on top.
👤
Personal
→
👥
Team
→
🛡
Organization
→
🤖
AI Providers
👤
Personal brain
Run a MemBrain on your own machine. Detected PII gets redacted at your edge before it reaches a shared brain. You add memory and policies on top of the team defaults.
👥
Team brain
Sales, Engineering, Legal — each team gets its own scoped brain with shared memory, specialized policies, and scoped knowledge. Teams collaborate independently; the org sees the trail.
🛡
Organization brain
The org-wide floor: threat detection, policy, and budgets enforced across configured teams and personal instances. Designed to keep detected PII from reaching external models — subject to your configured patterns and NER model.
Why MemBrain
How MemBrain compares
Most AI gateways do one or two of these well. MemBrain treats the brain functions as a single pipeline that shares state.
Threat Detection
Memory
Routing
Self-Hosted
Integrated
MemBrain
✓ 25+ patterns + ML
✓ Semantic store
✓ Privacy-aware
✓ Apache 2.0
✓ All connected
LiteLLM
✓ Plugin
—
✓ 100+ models
✓ MIT
— Isolated
Cloudflare
✓ DLP
—
— Limited
— SaaS only
— Isolated
Portkey
✓ Guardrails
—
✓ 250+ models
— Partial
— Isolated
Kong
✓ Plugin
— External
✓ Enterprise
— Commercial license
— Isolated
Comparison based on publicly documented capabilities as of May 2026. Competitor offerings change frequently — check their current docs for the latest.
How It Works
Deploy in minutes, not months
Whether you're one developer or an entire organization, MemBrain drops in without code changes.
👤
Personal
1
Install and run
docker compose up — your personal MemBrain is running in under 60 seconds.
2
Point your API calls at localhost
Set OPENAI_BASE_URL=http://localhost:8001/v1. Threat detection, memory, and judgment apply to every request routed through the gateway.
3
Your data stays yours
Detected PII gets redacted at your edge before it reaches a shared brain or an external model. You choose what to share.
🛡
Organization
1
Deploy at the org edge
Docker Compose, Kubernetes, or network proxy mode — fits your existing infrastructure.
2
Route all AI traffic through MemBrain
Org-wide threat detection, policies, and budgets enforced across configured teams.
3
Spin up team brains, enforce, audit
Give Sales, Engineering, and Legal their own brains. Import team memory, review audit logs, export compliance reports. Full visibility across every AI interaction.
Pricing
Start free, scale as you grow
Self-hosted and open core. Pay only for enterprise features.
Everything you need to know about getting started.
LiteLLM and Portkey route to models and bolt on plugins. MemBrain shares state across functions: threat detection scrubs PII before cache keys are computed, cached responses feed memory, memory enriches future prompts, all under one audit chain. The pipeline coupling is the whole point — it's not a collection of independent plugins.
No. MemBrain works as a drop-in proxy. Point your existing OpenAI or Anthropic SDK at the MemBrain gateway URL. For org-wide protection, deploy at the network level with a DNS override — no code changes, no agent installs, every AI tool covered.
OpenAI, Anthropic, and Ollama are supported natively. With the optional LiteLLM integration, you get access to 100+ models including Azure OpenAI, Google Gemini, AWS Bedrock, and more.
LLMs like GPT and Claude are the creative cortex — they generate language. But a real brain has memory (hippocampus), threat detection (amygdala), judgment (prefrontal cortex), and routing (thalamus). MemBrain provides these missing cognitive functions as software infrastructure. We call it a cognitive layer because it adds cognition around the model, not just a passthrough in front of it.
Yes. The Community tier is free forever and includes the core proxy, PII detection, dashboard, rate limits, budgets, caching, and full audit trail. Enterprise features require a license.
The Enterprise trial lasts 30 days with full access to every feature. No credit card required. After the trial, you can continue using the Community tier for free or upgrade.
Let your workforce move fast — safely
Join the waitlist to get early access and product updates.